论文:Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
作者:Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, Christian Theobalt
发表:SIGGRAPH 2023
生成满足用户需求的视觉内容,通常需要对生成对象的姿态、形状、表情和布局具有灵活而精确进行控制。现有的方法通过人工标注的训练数据或先前的 3D 模型来赋予生成对抗网络 (GANs) 可控性,这些方法通常缺乏灵活性、精确性和泛用性。在这项工作中,作者研究了一种功能强大但探索较少的控制 GAN 的方法,即以用户交互的方式“拖动”图像的任何点以精确到达目标点。为了实现这一目标,作者提出了 DragGAN ,它由两个主要部分组成:1) 基于特征的运动监督,驱动靶点向目标位置移动;2) 一种新的点跟踪方法,利用高区分度的生成器特征来保持靶点位置的局部化。借助 DragGAN ,任何人都可以通过精确控制像素的位置来变形图像,从而操纵姿势,形状,表情和各种类别的布局,如动物,汽车,人类,风景等。由于这些操作是在 GAN 学习的生成图像流形上执行的,因此即使对于具有挑战性的场景(例如遮挡的内容和遵循对象刚性的形变),它们也倾向于产生逼真的输出。定性和定量比较都证明了 DragGAN 在图像处理和点跟踪任务方面优于先前的方法。作者还展示了通过GAN反演对真实图像的处理。
研究背景
GAN
图像编辑
生成满足用户需求的视觉内容往往需要对生成对象的姿势、形状、表情和布局进行灵活和精确的控制。 现有方法通过手动注释的训练数据或先前的 3D 模型获得生成对抗网络 (GAN) 的可控性,这通常缺乏灵活性、精确性和通用性。
Diffusion: 自然语言无法对图像的空间属性进行细粒度控制,因此,所有文本条件方法都仅限于高级语义编辑。
理想的可控图像合成方法应具备以下特性: 1)灵活性:应能够控制生成的物体或动物的不同空间属性,包括位置、姿势、形状、表情和布局; 2)精确性:能够对空间属性进行高精度的控制; 3)通用性:应适用于不同的对象类别,但不限于某一类别。
主要工作
这项工作研究了一种强大但探索较少的控制 GAN 的方法,即以用户交互的方式“拖动”图像的任何点以精确到达目标点。 为实现这一目标,本文提出了 DragGAN,通过 DragGAN,任何人都可以通过精确控制像素的位置对图像进行变形,从而操纵动物、汽车、人类、风景等不同类别的姿势、形状、表情和布局。
DragGAN 允许用户“拖动”任何 GAN 生成图像的内容。 用户只需点击图像上的几个 handle point(红色)和 target point(蓝色),就可以移动 handle point 以精确到达其对应的 target point。 用户可以选择绘制 mask,保持图像的其余部分固定。
DragGAN 的核心为以下两个组件:1)基于特征的运动监督(Motion supervision),驱动 handle point 朝着 target point 移动。2)点跟踪(Point tracking),利用高区分度的生成器的特征来保证 handle point 的位置。具体来说,运动监督是通过优化潜在编码(latent code)的偏移特征块损失来实现的。每个优化步骤都会使 handle point 更接近目标;点跟踪随后通过在特征空间中进行最近邻搜索来执行。整个优化过程会反复进行直到 handle point 和 target point 重合。

运动监督 Motion supervision
DragGAN 基于 StyleGAN2 的模型架构。具体来说,作者考虑了 StyleGAN2 第 6 个块之后的特征图,这在所有层的特征图中表现最佳,因为它在分辨率和区分度之间有很好的平衡。作者观察到图像的空间属性主要受到前6层的 的影响,而剩下的层只影响外观。因此,只更新前6层的特征图,保持其他层不变以保留外观。这种选择性的优化导致图像内容的轻微移动,从而实现所期望的效果。
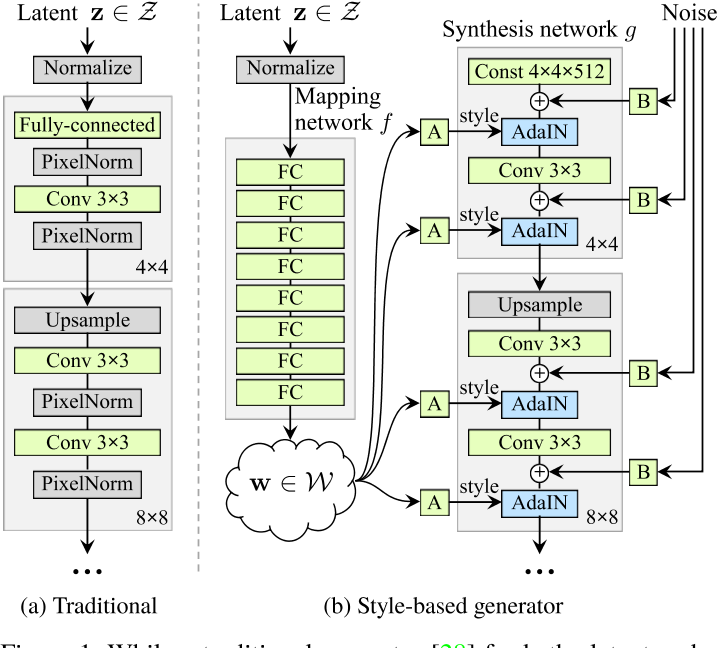

具体来说,StyleGAN 中的特征图分辨率随着层数增加而增加,因此将第六层的特征图 F 进行双线性插值来调整大小,使其与输出图像大小一致。
运动监督是通过优化隐空间编码 (latent code) 的损失函数来实现的。 每个优化步骤都会使得 handle point 更接近 target point;重复此优化过程,直到二者重合。 DragGAN 还允许用户有选择地绘制 Mask 以执行特定区域的编辑。
其中,$F(q)$ 表示在特征图 F 中 q 位置的特征值,$di = \frac {t_i-P_i}{||t_i-P_i||_2}$ 是从 $p𝑖$ 指向 $t_𝑖$ 的归一化向量,$F_0$ 初始图像对应的特征图。
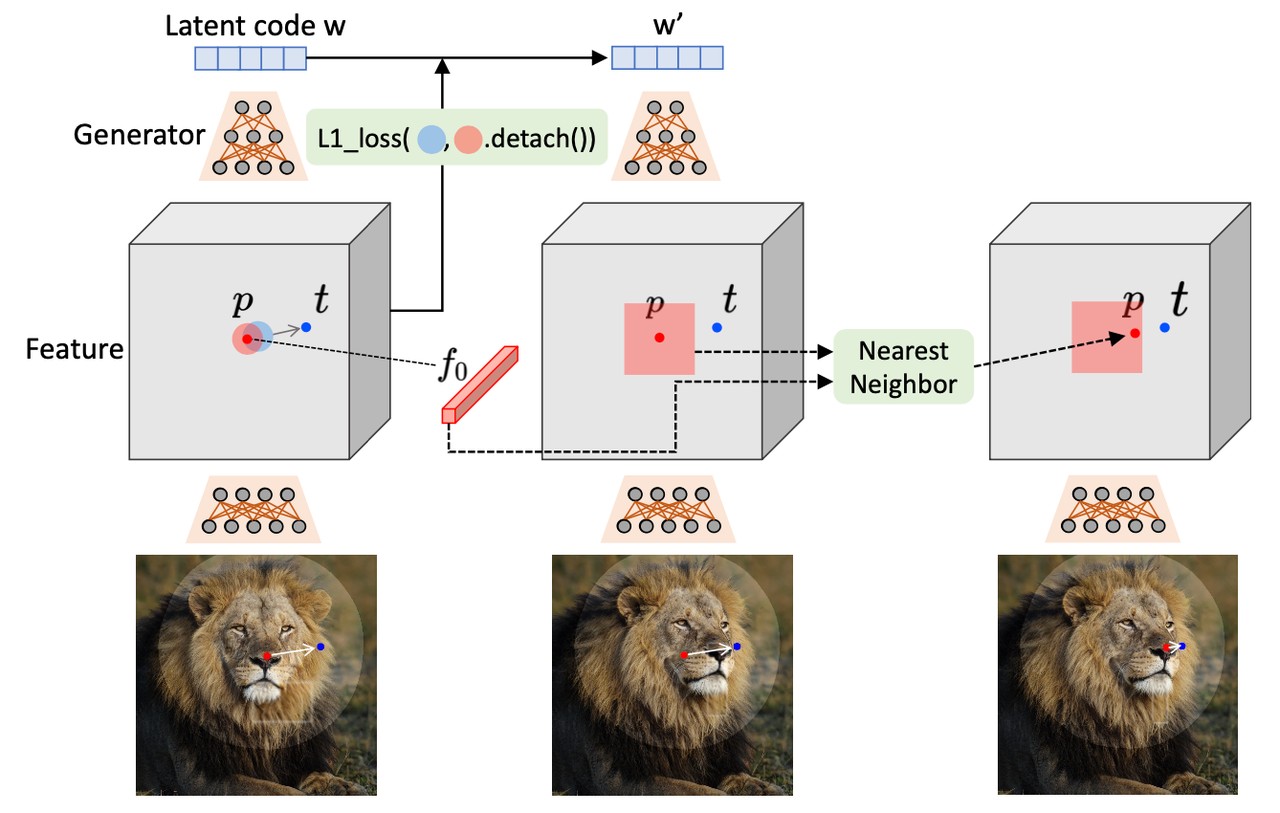
点追踪 Point Tracking
运动监督得到了新的潜在编码 $w^{‘}$、新的特征图 $F^{‘}$ 和新的图像 $I^{‘}$。由于运动监督步骤并没有直接提供处理点的精确新位置,因此点追踪的目的是更新handle point 的位置,使其跟踪物体上对应的点。点追踪通常通过光流估计模型实现。然而,这些额外的模型会显著影响效率,并且在 GAN 中可能会出现累积误差。因此,作者提出了一种适用于 GAN 的新的点追踪方法。核心在于利用 GAN 的高辨识度特征空间。可以通过特征块中的最近邻搜索来有效地进行跟踪。具体而言,将初始处理点的特征表示为 $fi=F_0(p_i)$ 。$p_i$ 周围的一定区域定义为 $\Omega_2(p_i, r_2) = {(x, y)|\ |x - x{p, i}| < r2,|y - y{p, i}| < r_2}$。然后通过在 $Ω_2(p_i, r_2)$ 中搜索 $f_i$ 的最近邻来获得追踪点的位置。
评估
由于 DragGAN 不依赖任何额外的网络,它实现了高效的操作,在大多数情况下,在比如单个 RTX 3090 GPU 上只需要几秒钟。 这允许进行实时的交互式编辑,用户可以在其中快速迭代不同的布局,直到获得所需的输出。
qualitative
与简单应用扭曲的传统形状变形方法不同 ,我们的变形是在 GAN 的学习图像流形上执行的,它往往遵循底层对象结构。例如,我们的方法可以产生被遮挡的内容,比如狮子嘴里的牙齿,并且可以随着物体的刚性而变形,比如马腿的弯曲。
quantitative
形变能力
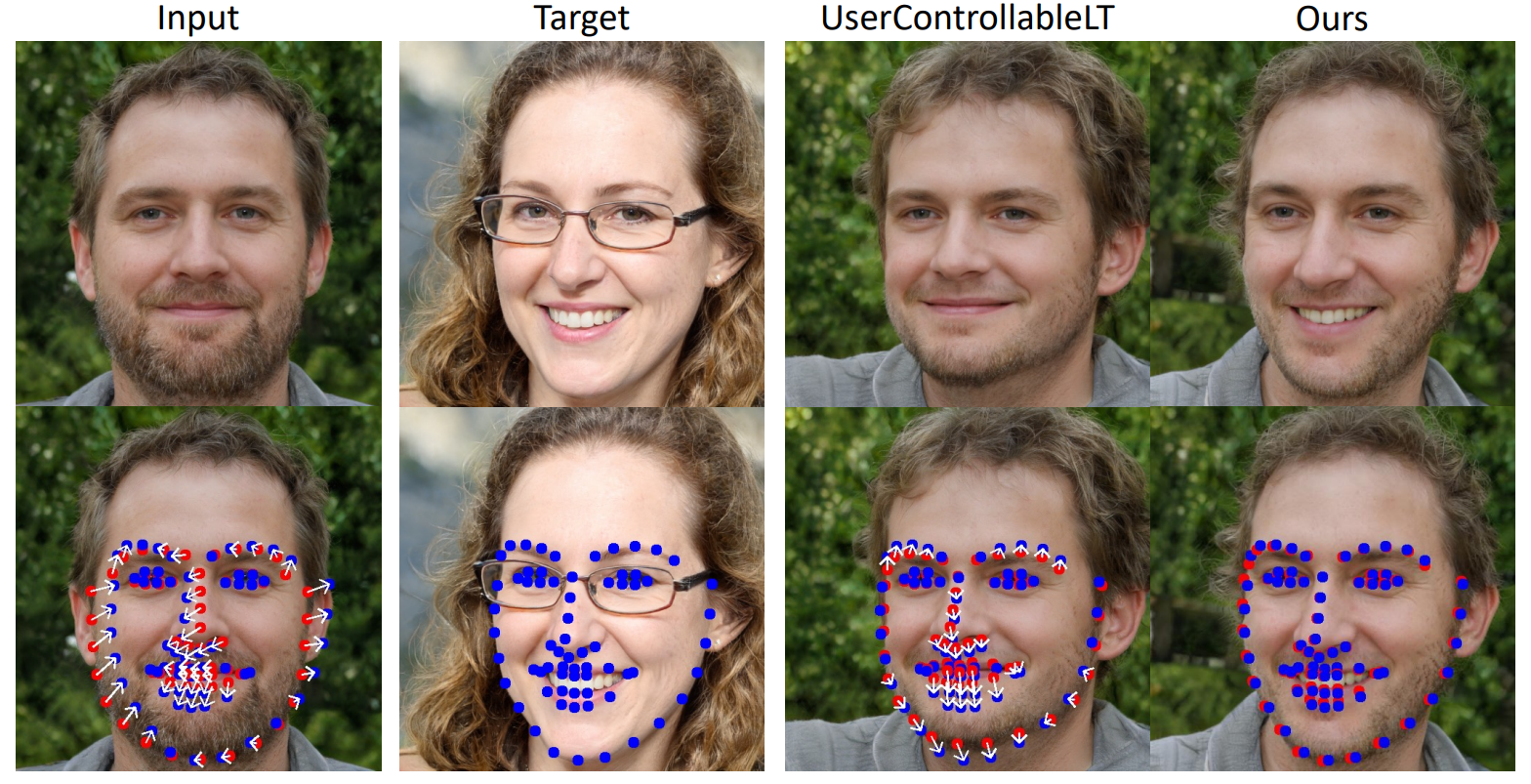
现有的 Face landmark 技术非常成熟,因此可以将其输出用作真实标签。具体来说,在 FFHQ 上训练的 StyleGAN 随机生成两张人脸图像并检测它们的 Face landmark 。目标是操纵第一幅图像的 landmark 以匹配第二幅图像的 landmark 。处理后,预测最终生成图像的 landmark 并计算到第二幅图像的 landmark 的平均距离(mean distance, MD)。最终的分数反映了该方法将 landmark 移动到目标位置的能力。在不同数量的 landmark(包括 1、5 和 68)的 3 种设置下进行评估。同时,使用编辑图像和初始图像之间的 FID 分数作为图像质量的指示。
定性比较如图所示,本方法张开嘴并调整下巴的形状以匹配目标面部,而 UserControllableLT 则无法做到这一点。此外,本方法保留了更好的图像质量,如 FID 分数所示。
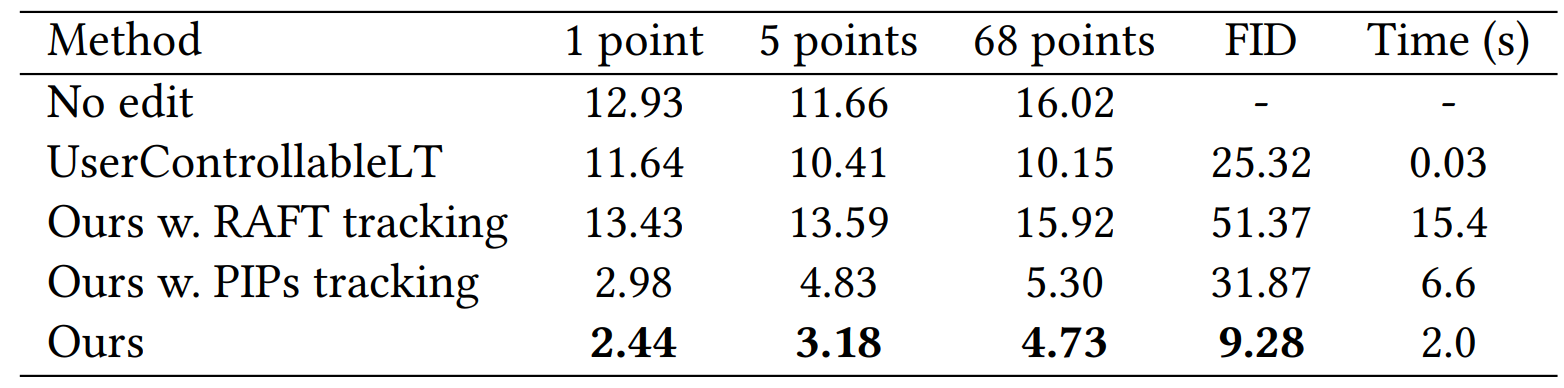
跟踪能力
本方法实现了比 RAFT 和 PIP 更准确的操作。不准确的跟踪会导致过度操作,从而降低图像质量,如 FID 分数所示。尽管 UserControllableLT 速度更快,但本方法在很大程度上提高了此任务的上限,实现了更符合用户需求的操作,同时维持在适当的运行时间内。
讨论
掩码 Effects of mask
该方法允许用户输入一个可移动的二值区域掩码。如下图所示当给出一只狗头的掩码时,其他区域几乎保持不变,只有头部移动。如果没有掩码,操作将移动整个狗的身体。这也表明,基于点的操作通常有多个可能的解决方案,GAN将倾向于在从训练数据中学到的图像流形中找到最接近的解决方案。掩码方式可以帮助减少歧义并保持某些区域固定。

超出分布 Out-of-distribution manipulation
DragGAN 具有一定的外推能力,可以创建超出训练图像分布的图像,例如狮子的极度张开的嘴和巨大的车轮。

真实图片编辑 Real image editing
使用 GAN inversion 技术将真实图像嵌入 StyleGAN 潜在空间,进而使用本方法来操纵真实图像。执行一系列操作来编辑图像中面部的姿势、头发、形状和表情。

局限性 Limitations
- 尽管具有一定程度的外推能力,但生成图片的质量仍受训练数据的多样性影响。如下图所示,创建与训练分布偏离的人体姿势可能会产生扭曲。
- 标记于纹理较少区域的 handle point 更倾向于在跟踪中产生偏移,因此建议尽可能选择纹理丰富的处理点。

- 难以处理包含多个物体的图片。

社会影响 Social impacts
由于 GragGAN 可以改变图像的空间属性,它可能被滥用来创建具有虚假姿势、表情或形状的真实人物图像。因此,任何使用 GragGAN 的应用或研究都必须严格遵守人格权利和隐私法规。
结论
在这项工作中,作者展示了在生成对抗网络生成的图像上进行点追踪可以在不使用额外神经网络的情况下实现。揭示了生成对抗网络的特征空间具有足够的区分能力,可以通过特征匹配简单实现追踪。这篇文章首次将基于点的编辑问题与高区分度的生成器的特征联系起来,并设计了具体的方法。摒弃额外的追踪模型使得该方法更高效。
Reference
[1] Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
[2] XingangPan/DragGAN: Official Code for DragGAN (github)
[4] Pivotal Tuning for Latent-based Editing of Real Images
[5] A Style-Based Generator Architecture for Generative Adversarial Networks
✉️ zjuvis@cad.zju.edu.cn